Time signal classification using Convolutional Neural Network in TensorFlow - Part 1
This example explores the possibility of using a Convolutional Neural Network(CNN) to classify time domain signal. The fundamental thesis of this work is that an arbitrarily long sampled time domain signal can be divided into short segments using a window function. These segments can be further converted to frequency domain data via Short Time Fourier Transform(STFT) . This approach is well known from acoustics, but it is easily applicable on any frequency spectrum. The goal of this work is to add an alternative tool to an ensemble of classifiers for time signal predictions. To illustrate, this specific classifier example was developed on VSB Power Line Fault Detection dataset where I aimed to combine three classifiers:
- Long Short-Term Memory (LSTM) Recurent Neural Network(RNN),
- Gradient Boosted Decision Tree using signal statistics, and finally the
- Convolutional Neural Network(CNN)
These three methods are based on very different principles and can complement each other with different sets of strengths and weaknesses.
Full example repo on GitHub
If you want to get the files for the full example, you can get it from this GitHub repo. You’ll find two files:
frequency domain TFRecord transformation.py
CNN_TFR_discharge_detection.py
Signal Processing
The Raw Data
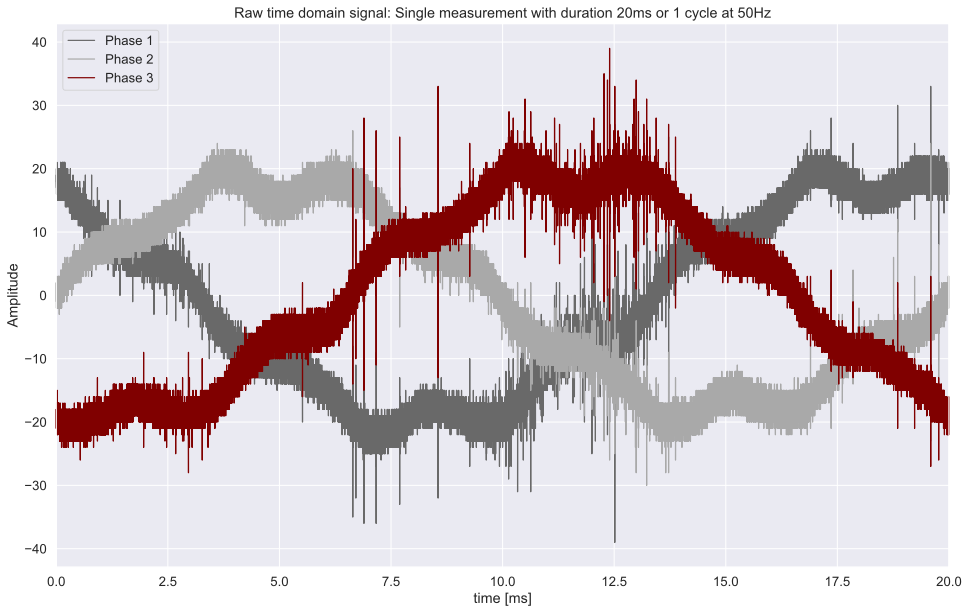
The raw dataset contains time domain measurements of a 3-phase transmission line. Each measurement contains three individual phase signals with 800 000 discrete data points covering 20ms (or one cycle at 50Hz). The following plot shows the data for a single measurement:
Each phase can have one class:
- 0: no fault / discharge
- 1: fault / discharge present
Therefore, for the purposes of this particular classifier, we take each individual phase signal as a single independent sample. As a result, in the raw form we have 800k features per sample and a binary classification problem.
Warning: We still must split the data into train/test based on measurements. Having different phases from a single measurement in both train and test datasets would most certainly lead to information leak!
Data Transformation
Here is a summary of what we know about the raw signal data:
- 1D tensor with length $800e5$
- Measurement length of $20ms$ gives us
- Sampling frequency $f_s=40MHz$
- STFT can reliably resolve frequency domain features up to $20MHz$ as per sampling theorem
With this knowledge, we can use scipy stft to transform the 1D time domain data into a 2D tensor of frequency domain features. That being said, the overall length of the data is still going to amount to $800e5$ datapoints. As an example, STFT with $nperseg=2000$ will return 2D array with a shape of 1000x800. To reduce the data size, we can use block_reduce with a stride of 4 and np.max function(works just like pooling in CNN).
Here is the complete function to execute this two step transformation:
def signal_stft(phase_data,plot = False):
fs = 40e6
f, t, Zxx = signal.stft(phase_data, fs, nperseg=1999,boundary = None)
reducedZ = block_reduce(np.abs(Zxx), block_size=(1, 1), func=np.max)
reducedf = f[0::1]
reducedt = t[0::1]
if plot:
plt.pcolormesh(reducedt, reducedf, reducedZ, vmin=0, vmax=0.5)
plt.title('STFT Magnitude Reduced')
plt.ylabel('Frequency [Hz]')
plt.xlabel('Time [ms]')
plt.show()
return reducedZ
The following image plot shows the output spectrogram from a single 20ms signal:
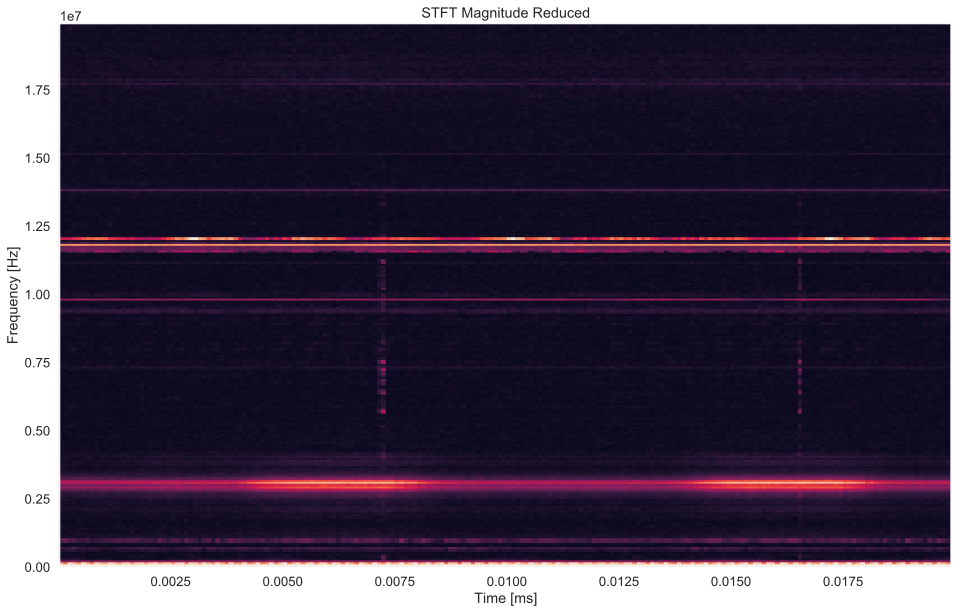
The final dimension is 250x200 points, which is a considerable reduction with acceptable information loss. Additionally, the resulting 2D tensor is more favorable to CNN architectures that most of us are familiar with from image classification.
Upsampling and TFrecords for Data Streaming
Since the transformed training data still requires gigabytes of memory, I save them into smaller TFRecords that will allow for smooth data streaming during CNN training in TensorFlow. This is described in more detail in this post.
The following code will split the measurement ids into train/test datasets while protecting phase signals from a single measurement being split. Since the classes are also highly unbalanced(about 14:1), the code will also upsample the minor class using permutation operations to avoid having duplicated samples. Note: Only train data is upsampled.
import pandas as pd
import tensorflow as tf
import numpy as np
import os
import pyarrow.parquet as pq
from scipy import signal
import matplotlib.pyplot as plt
from skimage.measure import block_reduce
import math
#%% PARAMETER SPECIFICATION
eval_fraction = 0.25 #fraction of data for evaluation purposes
#Specify location of the source and output data
data_path = 'G:\\powerLineData\\all\\'
output_path_predict = 'G:\\powerLineData\\TFR_predict_sfft\\'
os.listdir(data_path)
#Get the metadata for the entire training dataset
meta_train = pd.read_csv(data_path + 'metadata_test.csv')
measurement_id = np.array(meta_train['id_measurement'].unique())
#Randomly shuffle the measurement ids
np.random.shuffle(measurement_id)
#Split the id array into train and eval arrays
trainIDs, evalIDs = np.split(measurement_id,[int(len(measurement_id)*(1-eval_fraction))])
#Find how many disharges are in each measurement (int between 0 and 3) and create weight vector
trainWeights = np.zeros(len(trainIDs)).astype(int)
for i, ID in enumerate(trainIDs):
trainWeights[i] = sum(meta_train['target'].loc[meta_train['id_measurement'] == ID])
#%% Functions
# Function gets data of a specific measurement based on measurement_id
def get_measurement(ID):
columns=[str(i) for i in range(ID*3,ID*3+3,1)]
measurement = pq.read_pandas(data_path + 'test.parquet', columns).to_pandas()
return ID, measurement
# Function to parse a single record from the orig MNIST data into dict
def parser(signal, signal_ID, measurement_ID):
parsed_data = {
'signal': signal.flatten(order='C'), #Makes it 50000 float32 1D vector
'signal_ID': signal_ID,
'measurement_ID': measurement_ID,
'label': 9
}
return parsed_data
# Create the example object with features
def get_tensor_object(single_record):
tensor = tf.train.Example(features=tf.train.Features(feature={
'signal': tf.train.Feature(
float_list=tf.train.FloatList(value=single_record['signal'])),
'signal_ID': tf.train.Feature(
int64_list=tf.train.Int64List(value=[single_record['signal_ID']])),
'measurement_ID': tf.train.Feature(
int64_list=tf.train.Int64List(value=[single_record['measurement_ID']])),
'label': tf.train.Feature(
int64_list=tf.train.Int64List(value=[single_record['label']]))
}))
return tensor
# Execute STFT on phase signal data and reduce the resulting 2D matrix
def signal_stft(phase_data,plot = False):
fs = 40e6
f, t, Zxx = signal.stft(phase_data, fs, nperseg=1999,boundary = None)
reducedZ = block_reduce(np.abs(Zxx), block_size=(4, 4), func=np.max)
reducedf = f[0::4]
reducedt = t[0::4]
if plot:
plt.figure(figsize = (16, 10))
plt.pcolormesh(reducedt, reducedf, reducedZ, rasterized=True, linewidth=0, vmin=0, vmax=0.5)
plt.title('STFT Magnitude Reduced')
plt.ylabel('Frequency [Hz]')
plt.xlabel('Time [ms]')
plt.show()
return reducedZ
#%% Produce TFR files for Training (with upsampling and permutations)
def generate_TFR(IDs, measurements_per_file, output_path):
numFiles = math.ceil(len(IDs) / measurements_per_file)
for file_id in range(numFiles):
print('\n Creating file # %2d' %file_id)
with tf.python_io.TFRecordWriter(output_path + 'train_data_' + str(file_id) + '.tfrecord') as tfwriter:
measurements_left = len(IDs) - file_id * measurements_per_file
if measurements_left < measurements_per_file:
iterations = measurements_left
else:
iterations = measurements_per_file
# Iterate through all measurements
for i in range(iterations):
measurement = get_measurement(IDs[file_id * measurements_per_file + i])
def commit_record(measurement):
for j in range(3):
measurement_ID = measurement[0]
signal_ID = measurement[1].columns.values[j]
print(signal_ID)
#float32 of 250*200
signal_data = signal_stft(measurement[1][signal_ID].values)
parsed_data = parser(signal_data, int(signal_ID), measurement_ID)
record_tensor = get_tensor_object(parsed_data)
# Append tensor data into tfrecord file
tfwriter.write(record_tensor.SerializeToString())
commit_record(measurement)
#%% Execute functions
# Train IDs: List of mesurement IDs to export into TFR files
# Measurements_per_file: How many real measurements to save in each TFR file
# Upscale: True / False add artificially computed reords with discharges (improving class balance)
# Output path: folder path where to save the TFR files
#Generate TFR records for training data with upscaling
generate_TFR(measurement_id, measurements_per_file = 8, output_path = output_path_predict)
I will focus on using the preprocessed frequency domain data in a Convolutional Neural Network in part 2 of this mini-series.