TensorFlow 2 - CPU vs GPU Performance Comparison
TensorFlow 2 has finally became available this fall and as expected, it offers support for both standard CPU as well as GPU based deep learning. Since using GPU for deep learning task has became particularly popular topic after the release of NVIDIA’s Turing architecture, I was interested to get a closer look at how the CPU training speed compares to GPU while using the latest TF2 package.
In this test, I am using a local machine with:
- 8 core Ryzen 2700x CPU (16 threads, 20MB cache, 4.3GHz max boost)
- Nvidia RTX 2080 (8192MB GDDR6 memory)
- 32GB 3200MHZ DDR4 RAM
- Win 10
The test will compare the speed of a fairly standard task of training a Convolutional Neural Network using tensorflow==2.0.0-rc1 and tensorflow-gpu==2.0.0-rc1. The neural network has ~58 million parameters and I will benchmark the performance by running it for 10 epochs on a dataset with ~10k 256x256 images loaded via generator with image augmentation. The whole model is built using Keras, which offers considerably improved integration in TensorFLow 2.
CNN Model Used for the Benchmark
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 256, 256, 32) 896
_________________________________________________________________
batch_normalization (BatchNo (None, 256, 256, 32) 128
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 85, 85, 32) 0
_________________________________________________________________
dropout (Dropout) (None, 85, 85, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 85, 85, 64) 18496
_________________________________________________________________
batch_normalization_1 (Batch (None, 85, 85, 64) 256
_________________________________________________________________
conv2d_2 (Conv2D) (None, 85, 85, 64) 36928
_________________________________________________________________
batch_normalization_2 (Batch (None, 85, 85, 64) 256
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 42, 42, 64) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 42, 42, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 42, 42, 128) 73856
_________________________________________________________________
batch_normalization_3 (Batch (None, 42, 42, 128) 512
_________________________________________________________________
conv2d_4 (Conv2D) (None, 42, 42, 128) 147584
_________________________________________________________________
batch_normalization_4 (Batch (None, 42, 42, 128) 512
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 21, 21, 128) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 21, 21, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 56448) 0
_________________________________________________________________
dense (Dense) (None, 1024) 57803776
_________________________________________________________________
batch_normalization_5 (Batch (None, 1024) 4096
_________________________________________________________________
dropout_3 (Dropout) (None, 1024) 0
_________________________________________________________________
dense_1 (Dense) (None, 4) 4100
=================================================================
Total params: 58,091,396
Trainable params: 58,088,516
Non-trainable params: 2,880
_________________________________________________________________
Creating the Virtual Environments
To make the test ubiased by a whole lot dependencies in a cluttered environment, I created two new virtual environments for each version of TensorFlow 2.
Standard CPU based TensorFlow 2
conda create -n TF2_CPU_env python=3.8 anaconda
source activate TF2_CPU_env
pip install tensorflow==2.0.0-rc1
GPU based TensorFlow 2
conda create -n TF2_GPU_env python=3.8 anaconda
source activate TF2_GPU_env
pip install tensorflow-gpu==2.0.0-rc1
Note that you need to install CUDA devkit to allow proper TF2 functionality. You can learn more about the installation steps here: https://www.tensorflow.org/install/gpu#windows_setup
Training the CNN on CPU
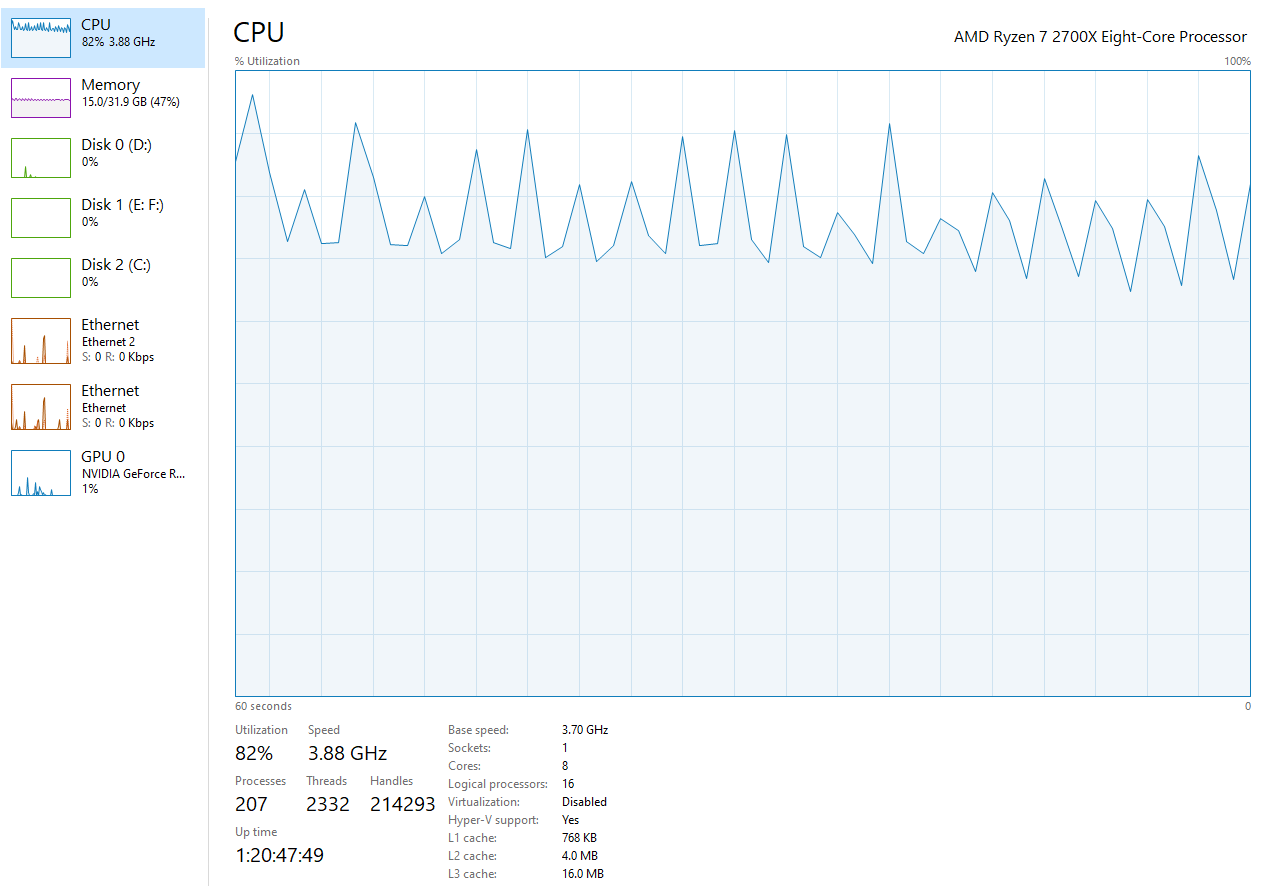
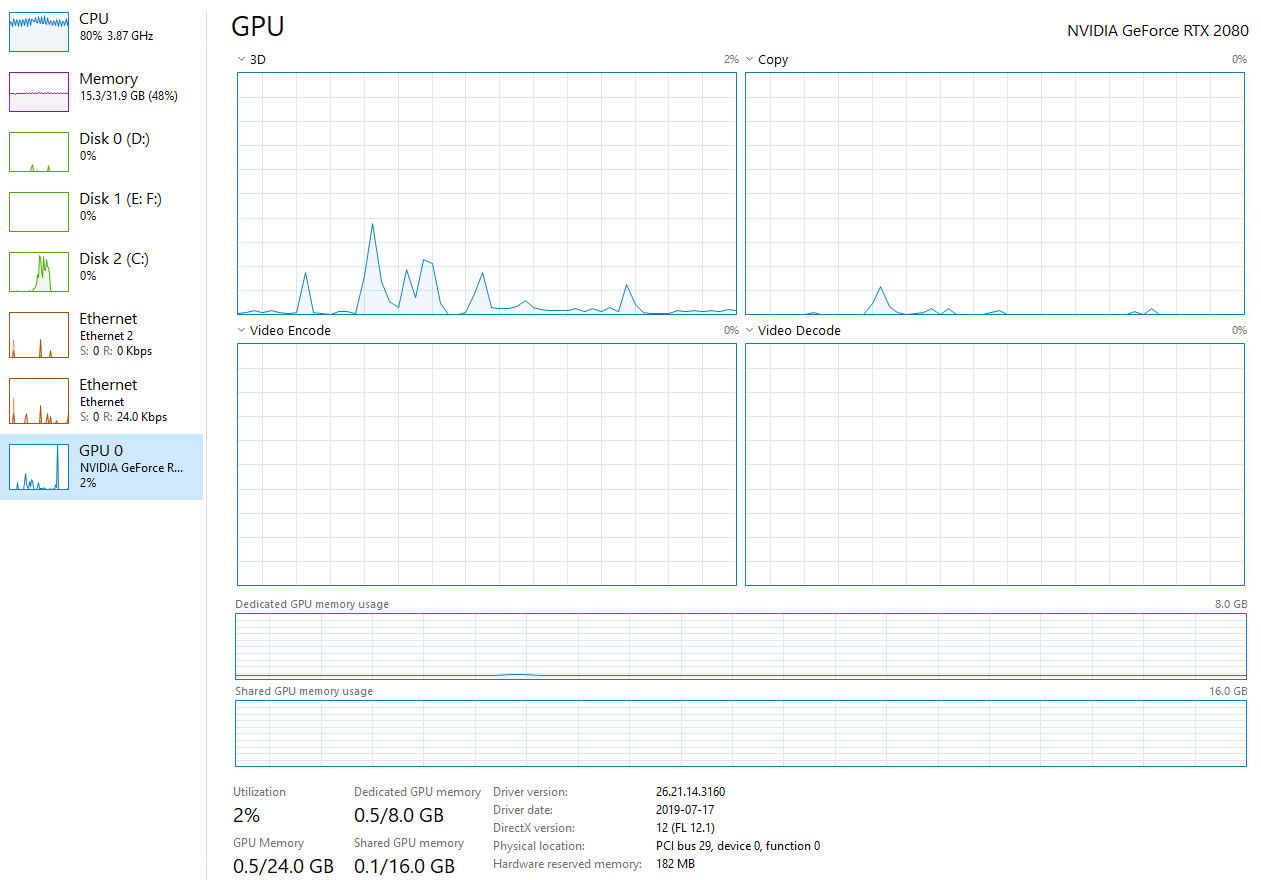
Using the CPU only, each Epoch took ~480 seconds or 3s per step. The resource monitor showed 80% CPU utilization while GPU utilization hovered around 1-2% with only 0.5 out of 8GB memory being used:
Detailed training breakdown over 10 epochs:
Epoch 1/10
153/153 [==============================] - 480s 3s/step - loss: 0.6639 - accuracy: 0.8010 - val_loss: 9.6215 - val_accuracy: 0.3034
Epoch 2/10
153/153 [==============================] - 477s 3s/step - loss: 0.3023 - accuracy: 0.9000 - val_loss: 6.4451 - val_accuracy: 0.3703
Epoch 3/10
153/153 [==============================] - 479s 3s/step - loss: 0.2673 - accuracy: 0.9051 - val_loss: 0.9108 - val_accuracy: 0.7945
Epoch 4/10
153/153 [==============================] - 478s 3s/step - loss: 0.2347 - accuracy: 0.9216 - val_loss: 0.8433 - val_accuracy: 0.7773
Epoch 5/10
153/153 [==============================] - 478s 3s/step - loss: 0.1809 - accuracy: 0.9382 - val_loss: 0.5569 - val_accuracy: 0.8377
Epoch 6/10
153/153 [==============================] - 477s 3s/step - loss: 0.1884 - accuracy: 0.9390 - val_loss: 1.8540 - val_accuracy: 0.6362
Epoch 7/10
153/153 [==============================] - 476s 3s/step - loss: 0.1771 - accuracy: 0.9363 - val_loss: 1.0628 - val_accuracy: 0.7993
Epoch 8/10
153/153 [==============================] - 480s 3s/step - loss: 0.1406 - accuracy: 0.9530 - val_loss: 0.4587 - val_accuracy: 0.8646
Epoch 9/10
153/153 [==============================] - 483s 3s/step - loss: 0.1222 - accuracy: 0.9585 - val_loss: 1.9671 - val_accuracy: 0.7325
Epoch 10/10
153/153 [==============================] - 479s 3s/step - loss: 0.1421 - accuracy: 0.9526 - val_loss: 0.4267 - val_accuracy: 0.8719
--- 4787.4720940589905 seconds ---
Training the CNN on GPU
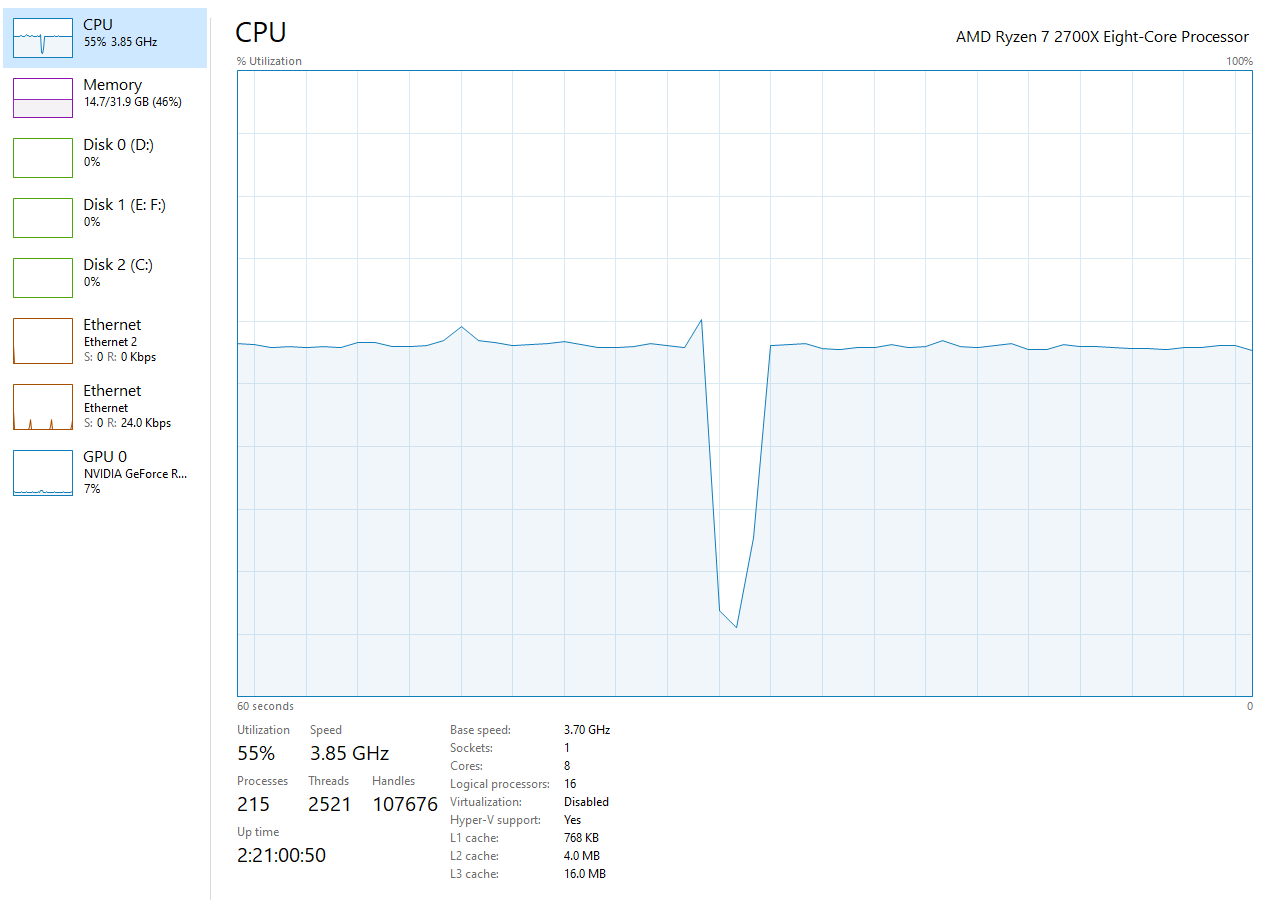
In contrast, after enabling the GPU version, it was immediately obvious that the training is considerably faster. Each Epoch took ~75 seconds or about 0.5s per step. That is results in 85% less training time. While using the GPU, the resource monitor showed CPU utilization below 60% while GPU utilization hovered around 11% with the 8GB memory being fully used:
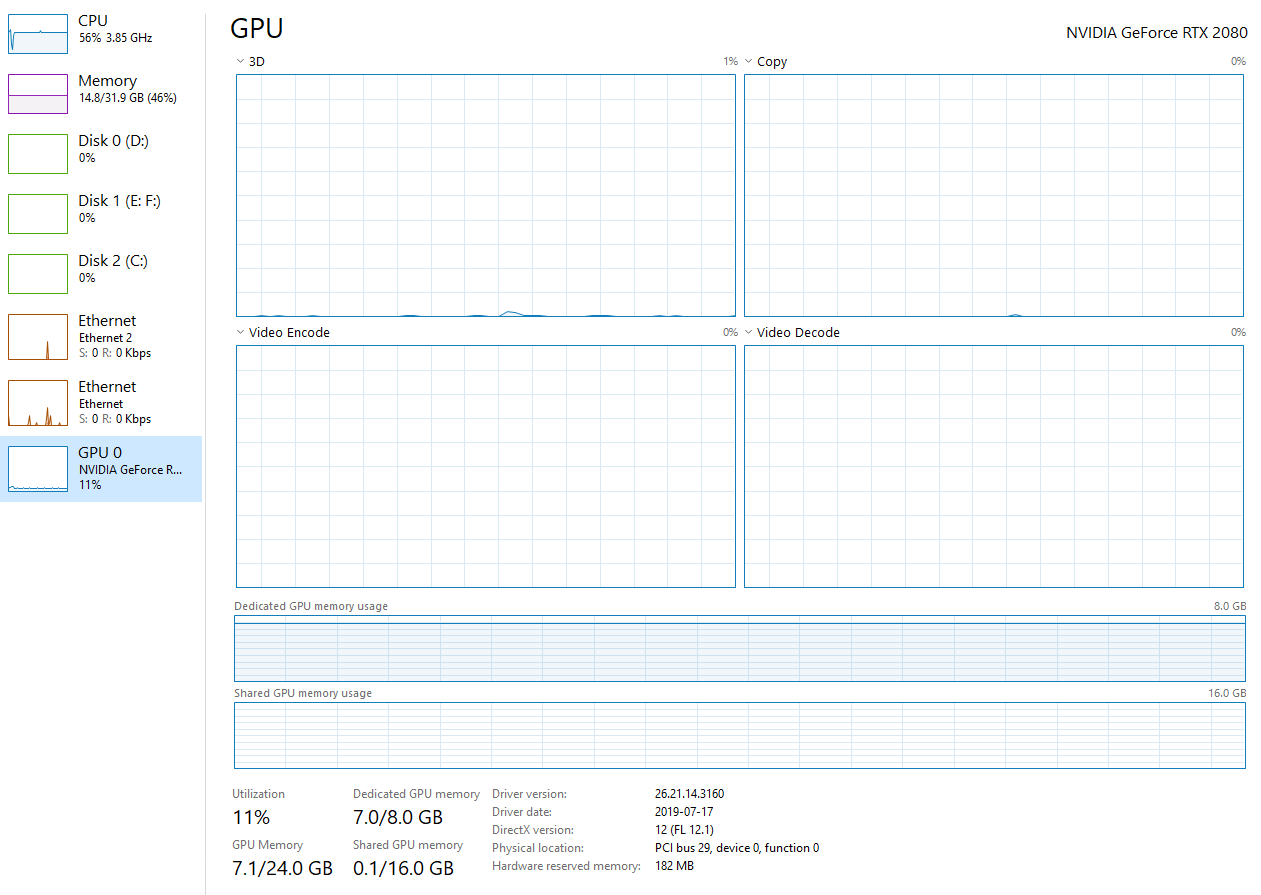
Detailed training breakdown over 10 epochs:
Epoch 1/10
153/153 [==============================] - 74s 484ms/step - loss: 0.5567 - accuracy: 0.8298 - val_loss: 10.9727 - val_accuracy: 0.3214
Epoch 2/10
153/153 [==============================] - 75s 493ms/step - loss: 0.2933 - accuracy: 0.9037 - val_loss: 5.2860 - val_accuracy: 0.5065
Epoch 3/10
153/153 [==============================] - 74s 486ms/step - loss: 0.2616 - accuracy: 0.9129 - val_loss: 1.4591 - val_accuracy: 0.6517
Epoch 4/10
153/153 [==============================] - 74s 485ms/step - loss: 0.2168 - accuracy: 0.9294 - val_loss: 0.3456 - val_accuracy: 0.9029
Epoch 5/10
153/153 [==============================] - 73s 480ms/step - loss: 0.1741 - accuracy: 0.9405 - val_loss: 0.9633 - val_accuracy: 0.8238
Epoch 6/10
153/153 [==============================] - 74s 483ms/step - loss: 0.1802 - accuracy: 0.9456 - val_loss: 1.5412 - val_accuracy: 0.7292
Epoch 7/10
153/153 [==============================] - 74s 482ms/step - loss: 0.1849 - accuracy: 0.9468 - val_loss: 0.3156 - val_accuracy: 0.9119
Epoch 8/10
153/153 [==============================] - 74s 486ms/step - loss: 0.1498 - accuracy: 0.9491 - val_loss: 0.6660 - val_accuracy: 0.8670
Epoch 9/10
153/153 [==============================] - 74s 483ms/step - loss: 0.1148 - accuracy: 0.9614 - val_loss: 0.7547 - val_accuracy: 0.8132
Epoch 10/10
153/153 [==============================] - 77s 503ms/step - loss: 0.0850 - accuracy: 0.9729 - val_loss: 0.7532 - val_accuracy: 0.8442
--- 745.4602980613708 seconds ---
The Conclusion
While setting up the GPU is slightly more complex, the performance gain is well worth it. In this specific case, the 2080 rtx GPU CNN trainig was more than 6x faster than using the Ryzen 2700x CPU only. In other words, using the GPU reduced the required training time by 85%. This becomes far more pronounced in a real life training scenarios where you can easily spend multiple days training a single model. In this case, the GPU can allow you to train one model overnight while the CPU would be crunching the data for most of your week.
Moreover, it seems that the main limiting factor for the GPU training was the available memory. It seems fair to assume that by tweaking the code and/or using GPU with more memory would further improve the performance. It seems that GPU training needs to become the default option in my toolkit.
Comparison summary
Package: tensorflow 2.0 tensorflow-gpu 2.0
Total Time [sec]: 4787 745
Seconds / Epoch: 480 75
Seconds / Step: 3 0.5
CPU Utilization: 80% 60%
GPU Utilization: 1% 11%
GPU Memory Used: 0.5GB 8GB (full)